Hive Pressure 2: How to Answer Hive Questions?
First, you need to learn how to ask good questions, and here are some of the resources that will help you to do so:
https://developers.hive.io/apidefinitions/
https://hive.hivesigner.com/
(Kudos to @inertia and @good-karma)
This set of API calls is far from perfect, but for now it has to be enough for general purpose API nodes.
https://www.youtube.com/watch?v=vlW9lDE3DuI
# The big, the slow, and the ugly.
Back in the days, we used to run a so-called “full node”, that is a single ~~`steemd`~~ (yeah, we haven’t renamed the binary yet) node that was built with `LOW_MEMORY_NODE=OFF` and `CLEAR_VOTES=OFF` and configured with all the plugins you can get.
It required a lot of RAM, it replayed for ages, and it was a huge pain to keep it running.
Our code is great for running blockchain. It’s not equally efficient when it has to answer complex questions.
# Current architecture
The idea is to move the workload requiring complex queries out of our blockchain nodes.
```
+----------+
| <-----------------+ @ @@@@@@ ,@@@@@%
| Hivemind | | @@@@ (@@@@@* @@@@@@
+-------+ | <-------+ | %@@@@@@ @@@@@@ %@@@@@,
| | +-----^----+ | | @@@@@@@@@@ @@@@@@ @@@@@@
| redis | | | | ,@@@@@@@@@@@@ @@@@@@ @@@@@@
| <--+ | +----v-----+ | @@@@@@@@@@@@@@@& @@@@@@ @@@@@@
+-------+ | +-v-+ | | | @@@@@@@@@@@@@@@@@@ .@@@@@% @@@@@@
| | <-----> AH node | | @@@@@@@@@@@@@@@@@@@@@( .@@@@@%
+-------+ +--> j | | | | @@@@@@@@@@@@@@@@@@@@ @@@@@@
<-------> | | u | +----------+ | *@@@@@@@@@@@@@@@@ @@@@@@ @@@@@@.
<-------> nginx <-----> s | | @@@@@@@@@@@@@@ &@@@@@. @@@@@@
<-------> | | s | +----------+ | #@@@@@@@@@@ @@@@@@ #@@@@@/
+-------+ | i | | | | @@@@@@@@ /@@@@@/ @@@@@@
| <-----> FAT node <---+ @@@@@( @@@@@@ .@@@@@&
+---+ | | @@ @@@@@& @@@@@@
+----------+
```
Sorry, lack of GIMP skills
## Hivemind
For this purpose I use Hivemind (hats off to @roadscape) backed by PostgreSQL.
> Hive is a "consensus interpretation" layer for the Hive blockchain, maintaining the state of social features such as post feeds, follows, and communities. Written in Python, it synchronizes an SQL database with chain state, providing developers with a more flexible/extensible alternative to the raw hived API.
## FAT node
Also, instead of a single `hived` node with all the plugins, I chose to run two nodes, one of them is a “fat node” (`LOW_MEMORY_NODE=OFF` and `CLEAR_VOTES=OFF`) on a MIRA-enabled instance to feed the Hivemind.
Please note that I have NOT included `market_history` in my configuration, simply because it doesn’t require a “fat node”, but Hivemind requires it, so make sure that you have it somewhere.
## AH node
Account history node is the other node I use in my setup. It serves not only account history, but it’s definitely the heaviest plugin here, hence the name.
I’m not using MIRA here, because I prefer the pre-MIRA implementation of the account history plugin and MIRA had some issues with it. Also, it’s way too slow for replay.
## Jussi
Instead of one service, I now have three specialized ones, I need to route incoming calls to them.
So the `get_account_history` goes to the AH node, while the `get_followers` goes to Hivemind.
That’s what jussi does, but it also caches things.
## Redis
Jussi uses Redis as in-memory data cache. This can very effectively take load off the nodes. Even though most of the entries quickly expire, it’s enough to effectively answer common questions such as “what’s in the head block?”

8 dApps asking for the latest block will result in 1 call to the node and 7 cache hits from Redis.
## Nginx
That’s the world facing component - here you can have your SSL termination, rate limiting, load balancing, and all other fancy stuff related to serving your clients.
# Resources
Now when you know all the components, let's take a look at what is required to run them all and (in the darkness) bind them.
## Small stuff
There are no specific needs here. The more traffic you expect, the more resources you will need, but they can run on any reasonable server on instance:
- Nginx needs what nginx usually needs - a bunch of cores and some RAM.
- Jussi is no different than nginx when it comes to resources.
- Redis needs what redis usually needs - a few GB of RAM to hold the data.
## Big stuff
- the AH node, which is non-MIRA in my setup, requires plenty of RAM for the `shared_memory.bin` file to either hold it on tmpfs or buffer/cache it, especially during replay. A machine with 32GB RAM will work, but I would rather suggest using a 64GB RAM machine these days. Of course, low latency storage such as SSD or NVMe is a must. You need 600GB of it.
- the FAT node in my setup is running MIRA, so it’s not that memory hungry, but the more RAM you have, the more effective it can be. A machine with 16GB RAM might work, but I would go with 32GB or 64GB for it. Don’t even try without a very fast SSD or NVMe. You need 400GB of it.
- Hivemind itself is a simple script, but it needs PostgreSQL as a database backend, and for that you need all the things that PostgreSQL usually needs. It can run on pretty much everything, as long as you have enough space to fit the data, currently 300GB. Of course, faster storage and more RAM will result in much better performance.
# From zero to hero
Reference hardware configuration:
```
Intel(R) Xeon(R) E-2274G CPU @ 4.00GHz
64GB RAM, ECC, 2666MT/s
2x NVMe 960GB (SAMSUNG PM983)
```
When you are starting from scratch, it’s best to get a recent `block_log`
I’m providing one at https://gtg.openhive.network/get/blockchain/
How fast you can get it depends on your network and load on my server. The average downloading speed is around 30MB/s, so you should be able to get it in less than 3 hours.
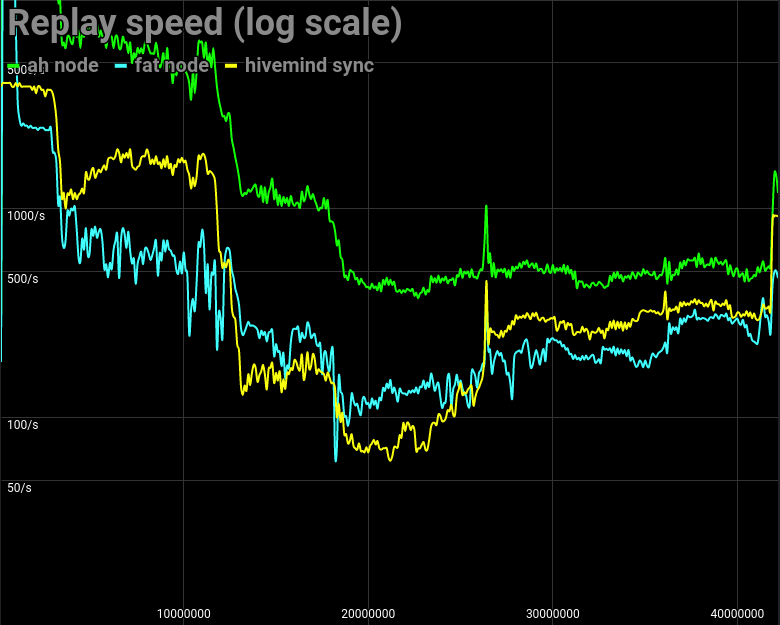
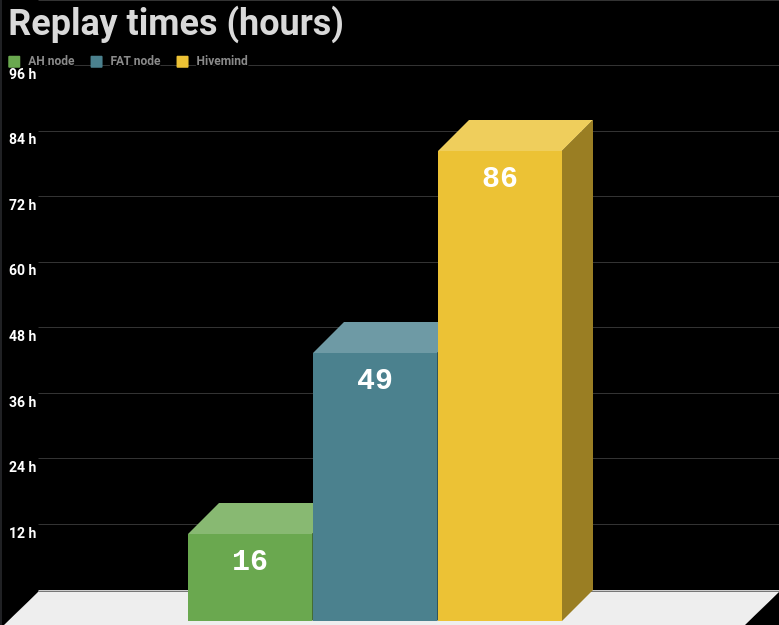
|Node type|Replay Time|
|---------|-------|
|AH Node |15 hours 42 minutes|
|Fat Node |48 hours 53 minutes|
|Hivemind |85 hours 50 minutes|
Roughly you need 4 days and 9 hours to have it synced to the latest head block.

A lot can be improved at the backend, and we are working on that. To be developer-friendly, we also need to improve the set of available API calls, finally get rid of the deprecated ones such as `get_state`, and move away from the all in one wrapper `condenser_api`. But that's a different story for a different occasion.
